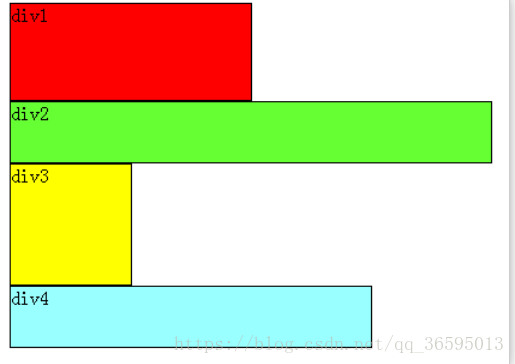
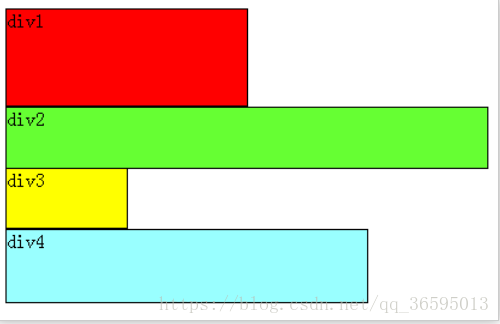
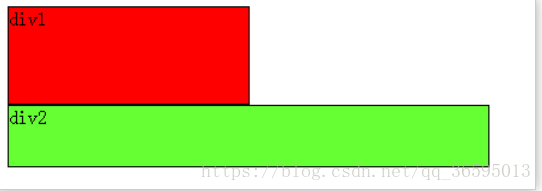
虚拟dom的实质就是用js来描述一个dom对象,这个dom对象包括标签名div,p等
属性class id等,还有子元素children
首先是html文件的简易实现,定义了2个DOM结构,在1s后触发patch算法,进行dom的更新和页面上的渲染1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
li {
color: red;
}
</style>
<script src="./vdom/vnode.js"></script>
<script src="./vdom/patch.js"></script>
</head>
<body>
<script>
var ul = new VNode("ul", { class: "ul" }, [
new VNode("p", { "class": "li" }, [], 'virtual,dom'),
new VNode("li", { "class": "li" }, [], "mvvm"),
new VNode('li', { class: 'li' }, [], 'virtual dom'),
new VNode('input', { type: 'text' }),
new VNode('li', { class: 'li' }, [], 'virtual dom'),
new VNode('li', {}, [], 'mvvm'),
new VNode('li', { class: 'li' }, [], 'buppt')
]);
var ul2 = new VNode('ul', { class: 'ul' }, [
new VNode('li', { class: 'li' }, [], 'buppt'),
new VNode('li', { class: 'li' }, [], 'mvvm'),
new VNode('p', {}, [], 'h1 dom'),
new VNode('li', { class: 'li' }, [], 'h1 dom'),
new VNode('div', {}, [], 'h1 dom'),
new VNode('input', { type: 'text' }, []),
]);
document.body.appendChild(ul.render());
setTimeout(() => {
console.log("vnode changed");
patch(ul, ul2);
}, 2000);
</script>
</body>
</html>
vnode表示对应的dom节点的js描述。主要定义了有哪些属性,还有render方法
调用createElement来渲染成真实的dom结构1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40class VNode {
constructor(tagName, props = {}, children = [], text = '') {
//主要记录一个虚拟元素节点的标签名称,属性,子节点,文本内容,对应
//的真实虚拟dom中的element元素,render函数是将这个虚拟的元素节点
//渲染成真正的一个真实dom节点的过程
this.tagName = tagName;
this.props = props;
this.children = children;
this.text = text;
this.key = props && props.key;
var count = 0;
children.forEach(child => {
if (child instanceof VNode)
count += child.count;
count++;
});
this.count = count;
};
render () {
//将虚拟dom生成真实的dom
let element = document.createElement(this.tagName);
for (let key in this.props) {
//设置属性
element.setAttribute(key, this.props[key]);
}
//添加子元素
for (let child of this.children) {
if (child instanceof VNode) {
//递归调用自己 将子元素一个个添加进父元素中
element.appendChild(child.render());
}
}
if (this.text) {
element.appendChild(document.createTextNode(this.text));
}
this.elm = element;
console.log(element);
return element;
}
}
patch算法,拿到两个vnode类后,进行对比,diff算法的本质类似于树的层次遍历,
所以时间复杂度是O(N)。在拿到两个vnode类后,首先判断父节点的属性是否是相同的,如果是不相同的。直接进行替换。不用管子元素。
随后再判断若2个都是文本节点,再进行文本的替换,如果新的节点有子元素,老的没有,则进行添加。老的有,新的没有,则进行删除。否则后续才是真正的updateChildren的方法
patch方法定义1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function patch (oldVnode, vnode) {
//新老虚拟dom节点的比较
if (isUndef(vnode))
return;
if (oldVnode === vnode) //判断同一层树的结构有没有发生变化
return;
if (isSameVNode(oldVnode, vnode)) //只有在父元素 例如属性 节点名称一样的情况下再去比较子元素
patchVnode(oldVnode, vnode);
else {
//不是相同节点 老的虚拟dom中的父元素节点找到,随后进行插入,将老的删除,新的添加
const ParentElm = oldVnode.elm.parentNode;
createElm(vnode, ParentElm, oldVnode.elm);
removeVnodes(parentElm, [oldVnode], 0, 0);
}
};
属性相同了再判断是不是文本节点,是就替换,还有子元素是否有进行比较,2者都有才进行updateChildren方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22function patchVnode (oldVnode, vnode) {
//将孩子节点拿到
var ch = vnode.children;
var oldCh = oldVnode.children;
//如果不是文本节点 首先判断父元素是否属性相同,属性相同的情况下再去判断是不是
//文本元素,如果是文本元素就直接替换掉 否则再比较子元素
if (isUndef(vnode.text)) {
if (isDef(ch) && isDef(oldCh)) {
//就进行新前 新后的一些遍历算法 //如果都有子元素 且子元素和新元素d
updateChildren(oldVnode.elm, oldCh, ch);
} else if (isDef(ch)) {
if (isDef(ch.text)) {
setTextContent(oldVnode.elm, '');
addVnodes(oldVnode, ch, 0, ch.length - 1);
} else if (isDef(oldCh)) {
removeVnodes(oldVnode.elm, oldCh, 0, oldCh.length - 1);
}
}
} else {
setTextContent(oldVnode.elm, vnode.text);
}
}
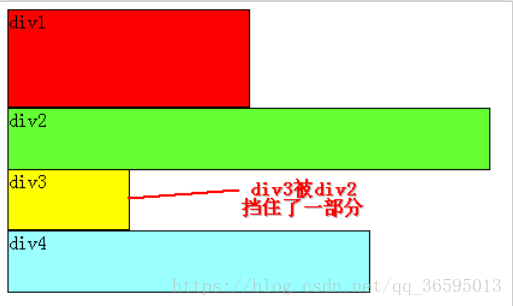
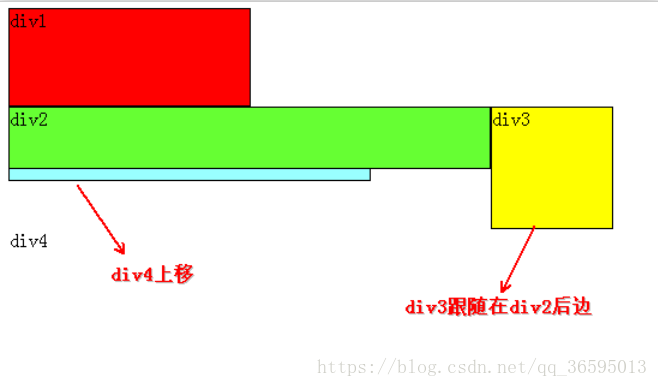
定义4个下标,新前,旧前,新后,旧后,进行新前与新前,新后与旧后,新前与旧后,
新后与旧前的比较。若都不满足,如果当前元素有key的话,去老树中找该key的节点。
没有key则将新树的头与老树的头到尾一一比较下来。如果有相同的,就把老树的这个节点移动到老树的头前,newStartIdx++;如果没有相同的,就新建这个节点,插到老树的头前,newStartIdx++。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62function updateChildren(parentElm, oldCh, newCh,){
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx, idxInOld, vnodeToMove, refElm
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(oldStartVnode, newEndVnode)
insertBefore(parentElm, oldStartVnode.elm, oldEndVnode.elm.nextSibling)
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(oldEndVnode, newStartVnode)
insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) {
createElm(newStartVnode, parentElm, oldStartVnode.elm)
} else {
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(vnodeToMove, newStartVnode)
oldCh[idxInOld] = undefined
insertBefore(parentElm,vnodeToMove.elm, oldStartVnode.elm)
} else {
createElm(newStartVnode, parentElm, oldStartVnode.elm)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(parentElm, newCh, newStartIdx, newEndIdx)
} else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}
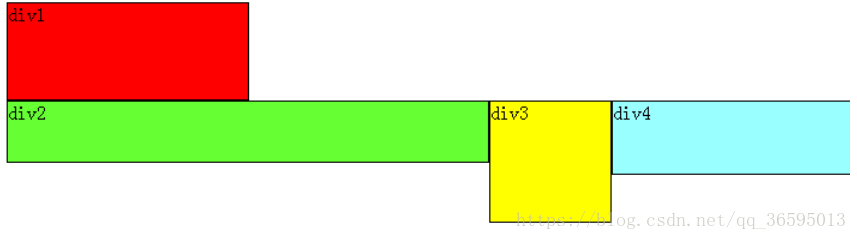
当oldStartIndex > oldEndIndex时,表明老的遍历完,新的没有遍历完,就添加新的
当newStartIndex > newEndIndex时,表明新的遍历完,老的没有遍历完,就删除老的
参考博客:https://www.cnblogs.com/wind-lanyan/p/9061684.html
github地址:https://github.com/buppt/virtual-dom-mvvm
https://github.com/KevinSwiftiOS/VueVirtual-DOM