过拟合与欠拟合
欠拟合指的是模型不能在训练集上获得足够低的训练误差。
过拟合指的是训练误差和测试误差(泛化误差)的差距比较大。
在评价指标上,就是模型在训练集上表现比较好,但是在测试集或者新数据上则表现比较差。
减少测试误差(泛化误差,过拟合)的方法统称为正则化,这些方法以增大训练误差为代价。
降低模型复杂度:
1.神经网络:减少网络层,神经元个数
决策树:降低树的深度,剪枝。
权重约束:
L1,L2正则化。
集成学习:
神经网络:Dropout
决策树:随机森林,GBDT。
反向传播算法
概述:梯度下降法需要利用损失函数对所有参数的梯度来寻找局部最小值。
反向传播算法就是用于计算该梯度的具体方法,其本质是利用链式法则对每个参数求偏导。
激活函数
使用激活函数的目的是为了向网络中加入非线性因素,加强网络的表示能力,解决线性模型无法解决的问题。
整流线性单元 ReLU
RELU 通常是激活函数较好的默认选择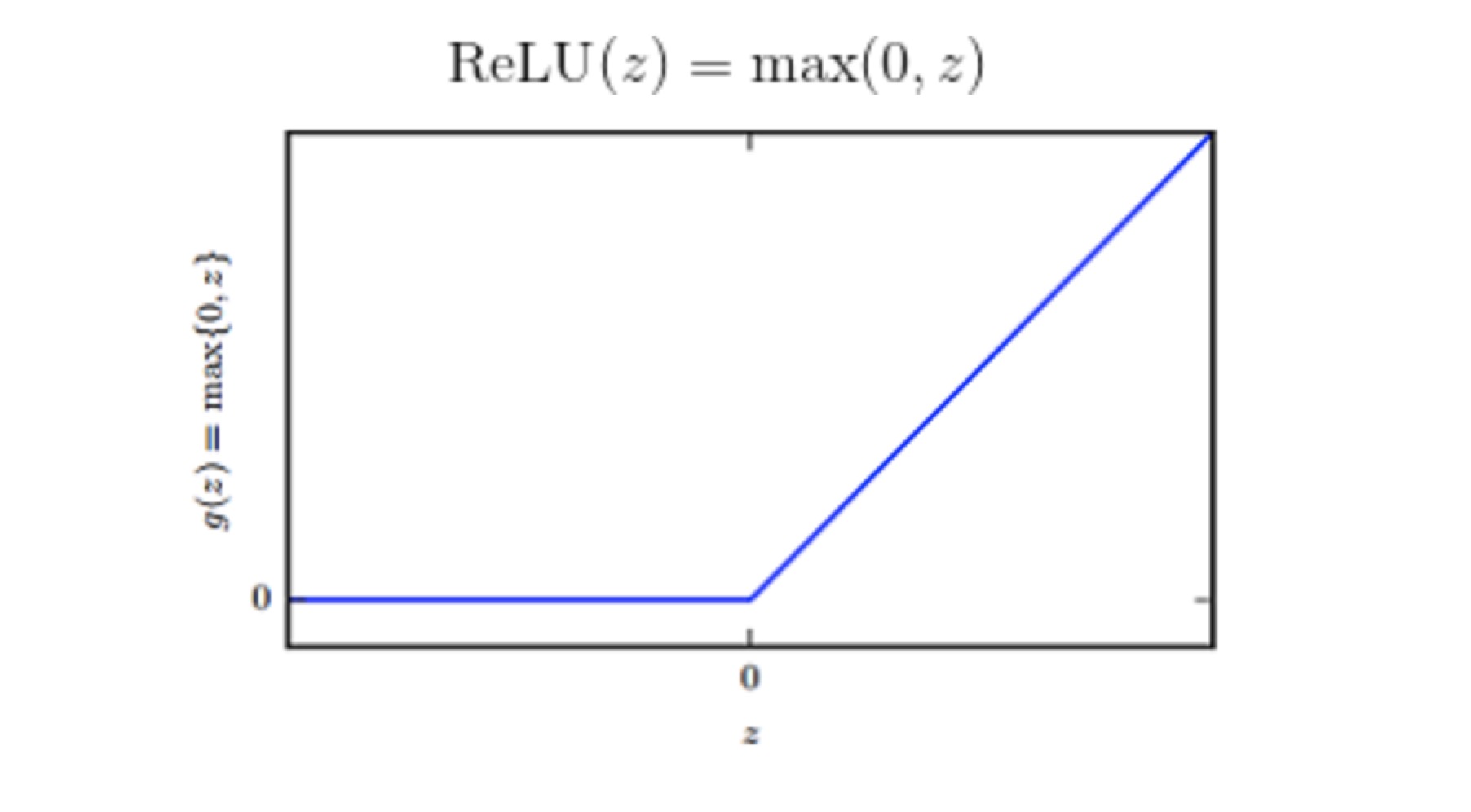
sigmoid与tanh激活函数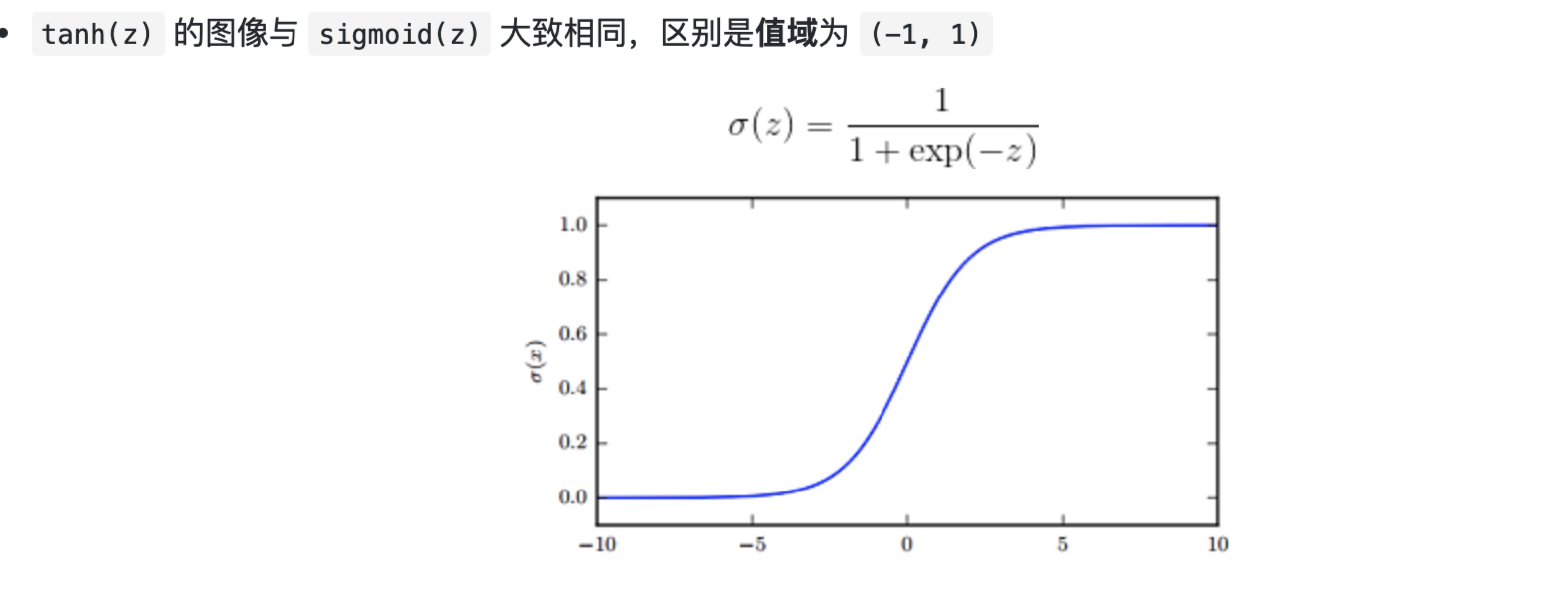
relu的优势
1.避免梯度消失 2.减缓过拟合 3.加速计算
正则化(Batch Normalization 批标准化)
BN是一种正则化方法(减少泛化误差),
加速网络的训练,防止过拟合,降低了参数初始化的要求。
动机
训练的本质是学习数据分布,如果训练数据和测试数据的分布不同会降低模型的泛化能力,因此,在开始训练前要对所有输入数据做归一化处理,其实质是让他们分布在同一个区间上,例如(-1,1)内
基本原理:
BN 方法会针对每一批数据,在网络的每一层输入之前增加归一化处理,使输入的均值为 0,标准差为 1。目的是将数据限制在统一的分布下。
BN也可以看做在各层之间加入了一个新的计算层,对数据分布进行额外的约束,从而增强模型的泛化能力。
L1/L2范数正则化
作用:限制模型的学习能力-通过限制参数的规模,使模型偏好于权重比较小的目标函数,防止过拟合
不同点
L1 正则化可以产生更稀疏的权值矩阵,可以用于特征选择,同时一定程度上防止过拟合;L2 正则化主要用于防止模型过拟合
L1 正则化适用于特征之间有关联的情况;L2 正则化适用于特征之间没有关联的情况。
L1/L2正则化优点
L1 & L2 正则化会使模型偏好于更小的权值。
更小的权值意味着更低的模型复杂度;添加 L1 & L2 正则化相当于为模型添加了某种先验,限制了参数的分布,从而降低了模型的复杂度。
模型的复杂度降低,意味着模型对于噪声与异常点的抗干扰性的能力增强,从而提高模型的泛化能力。——直观来说,就是对训练数据的拟合刚刚好,不会过分拟合训练数据(比如异常点,噪声)——奥卡姆剃刀原理