RNN与LSTM
中文分词,词性标注,命名实体识别,机器翻译等都是属于序列挖掘的范畴,序列挖掘的特点是某一步的输出不仅依赖于这一步的输入,还依赖于其他步的输入或输出,序列挖掘领域的机器算法有HMM(隐马尔科夫模型),和CRF(条件随机场)模型,近年来又开始流行RNN
RNN的网络结构: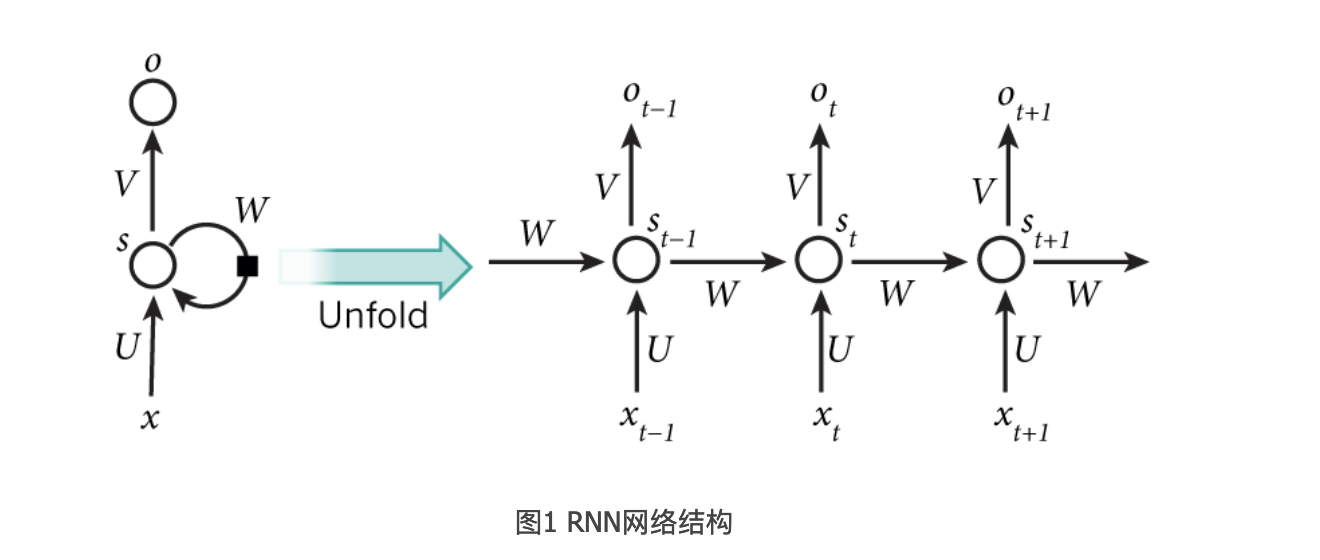
比如一个句子有5个词,要给5个词做词性标注,那相应的RNN就是5层的神经网络,每一层的输入时一个词,输出就是这个词的词性,
xt是第t层的输入,它可以是一个词的one-hot向量,也可以是分布表示(distributed repressentation)向量。
st是第t层的隐藏状态,负责整个神经网络的记忆功能,st是由上一层的隐藏状态和这一层的输入来共同决定的。
st = f(Uxt + Wst-1) f通常是个非线性的激活函数,比如tanh或者relu
由于每层的st都会向后一直传递,所以理论上st能够捕获到前面每一层发生的事情。
ot是第t层的输出,比如我们预测下一个词是什么的时候,ot就是一个长度为V的向量,V是所有词的总数,ot[i]表示下一个词是wi的概率,我们用softmax函数对这些概率进行归一化,ot = softmax(Vst)
每一层的U,W,V是共享的,这样极大的缩小了参数空间。
值得注意的是**每一层并不一定都有输入和输出,隐藏单元是RNN的必备武器,比如句子进行情感分析的时候,只需要最后一层给一个输出即可。
LSTM结构: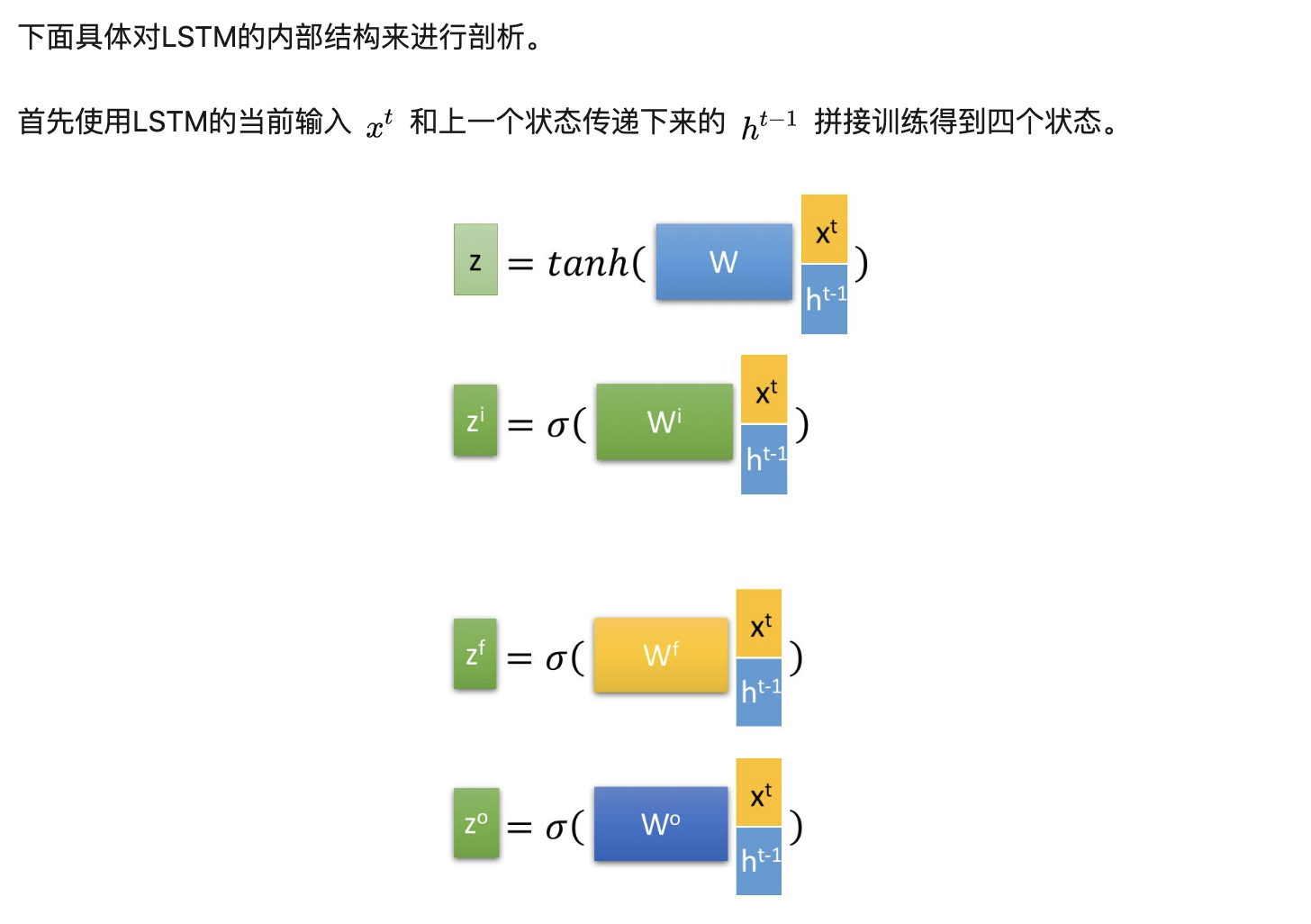
- 忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
具体来说是通过计算得到的 z^f (f表示forget)来作为忘记门控,来控制上一个状态的 c^{t-1} 哪些需要留哪些需要忘。
- 选择记忆阶段,这个阶段将这个阶段的输入有选择性地进行’记忆’,主要是会对输入xt进行选择性的记忆,哪些重要的就记录下来,哪些不重要的,就不要记录下来,当前的输入内容由前面计算得到的z表示。而选择的门控信号则是由 z^i (i代表information)来进行控制。
- 输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过 z^o 来进行控制的。并且还对上一阶段得到的 c^o 进行了放缩(通过一个tanh激活函数进行变化)。
与普通RNN类似,输出 y^t 往往最终也是通过 h^t 变化得到。
主要就是忘记阶段,将前面的哪些部分进行遗忘,记忆阶段,将现阶段的哪些部分进行记录,输出部分,这个阶段决定哪些将会被当成当前状态进行输出。
知乎上链接为https://zhuanlan.zhihu.com/p/32085405